E aí, pessoal ?
Voltamos com mais uma postagem sobre projeto de sistemas.
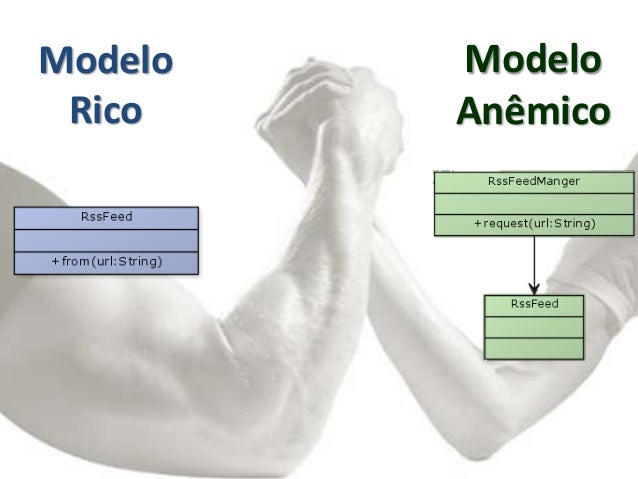
Dessa vez, o assunto é sobre modelo anêmico e modelo rico. O que será isso, hein ?
Para ficar por dentro da discussão sugiro ouvir o Podcast 11: Modelo Anêmico e Rico no qual foi baseado esse post.
No podcast, de acordo com o Alexandre Valente, modelo anêmico é basicamente aquele modelo que tem as regras de negócio um pouco isoladas das entidades de domínio. Já no modelo rico, as regras estão um pouco melhor distribuídas entre as entidades.
E por que será que dá tanto pano para a manga falar desse assunto ?
Porque, como a maioria das decisões de projeto, cada modelo há seu pró e contra. Vamos discutir um pouco sobre isso.
No podcast, o Alexandre Valente defendeu bastante o modelo anêmico, por ter tido boas experiências com ele e não tão boas assim com o outro. Para ele, a principal vantagem desse modelo é a produtividade. No entanto, para o Giovanni Bassi, esse modelo é um problema. Produtividade não é justificativa, já que, na sua opinião, ele poderia ser mais produtivo tendo um ambiente de desenvolvimento que segue o modelo rico. Para o Giovanni, o modelo anêmico é muito focado nos dados, o que torna as tarefas de teste muito mais difíceis. Já o modelo rico, é mais focado em comportamento e não em dados, sendo assim, mais fáceis de testar. Quanto maior o sistema, mais importante ter comportamento e não dados.
Após alguns prós e contras, quem vocês acham que ganha no quesito mercado ?
Foi o que eu pensei, o modelo anêmico!
Para uma pessoa começar no modelo rico, ela tem que entender bastante do negócio e da ideia da orientação a objetos. No mercado, não se muito tempo para isso, então as pessoas acabam debandando para o modelo anêmico, até sem perceber.
Toda essa discussão não quer dizer que o modelo anêmico é a maneira errada de programar e o modelo rico é o certo. Isso depende bastante da sua aplicação e do nível de maturidade/conhecimento da equipe. A ideia é manter o equilíbrio.
Até a próxima galera! :)
Comentários
Postar um comentário